


Terraform Advanced Topics and Best Practices for DevOps Engineers
Day 7 #TerraWeek


📝Introduction
Today, in this blog post, we will cover some advanced topics of Terraform Workspaces, Remote Execution, Collaboration, Code Organization in Terraform, Version Control with Terraform, CI/CD Integration with Terraform, Terraform Cloud, Terraform Enterprise and to end Terraform Registry.
This is part of #Day 7 and the last day of the #TerraWeek challenge initiated by Shubham Londhe.
I am so grateful to Shubham Londhe for this super opportunity to learn and improve my knowledge even more on Cloud and DevOps technologies with this challenge forcing us to go in search of more knowledge.
📝Terraform Workspaces
Workspaces are used to manage multiple instances of the same infrastructure within a single Terraform configuration.
It allows you to create and manage separate sets of resources for different environments (e.g., development, staging, production).
Each workspace maintains its own state file, ensuring isolation and preventing interference between environments.
However, you must manage your workspaces in the CLI and be aware of the workspace you are working in to avoid accidentally performing operations in the wrong environment.
Terraform configuration files (e.g., main.tf, variables.tf) remain the same across workspaces, promoting code reusability.
Workspaces can have different backend configurations, allowing you to store state files in separate locations if you're using a remote backend.
All Terraform configurations start in the default workspace. Type terraform workspace --help to have Terraform print out with all the commands you can use for workspaces.
$ terraform workspace --help

To verify the current workspace which is selected and denoted by a *.
$ terraform workspace list

To create a new workspace and enable you to switch between different environments:
$ terraform workspace new stagging
$ terraform workspace select stagging
$ terraform workspace list

📝Terraform Remote Execution
Remote-exec provisioner is always going to work on the remote machine outside of your local machine.
It offers several benefits, including centralized state management, collaboration features, and enhanced security.
This can be used to run a configuration management tool, bootstrap into a cluster, etc.
Multiple team members can work with the same infrastructure code, enabling easier coordination and consistent state management.
It can be used inside the Terraform resource object and in that case, it will be invoked once the resource is created, or it can be used inside a null resource which is usually the best approach as it separates this non-terraform behaviour from the real terraform behaviour.
i.e.
resource "aws_instance" "web" {
# ...
# Establishes connection to be used by all
# generic remote provisioners (i.e. file/remote-exec)
connection {
type = "ssh"
user = "root"
password = var.root_password
host = self.public_ip
}
provisioner "remote-exec" {
inline = [
"puppet apply",
"consul join ${aws_instance.web.private_ip}",
]
}
}
📝Terraform Collaboration
Terraform provides a collaborative workflow for teams to safely and efficiently create and update infrastructure at scale.
When groups of people collaborate using Terraform, they can achieve real, transformational benefits from infrastructure as code(IaC).
Terraform Pro is designed for teams to collaborate on and organize many Terraform states, configurations, modules, and variables. At the core of that collaboration is their integration with version control systems like GitHub to take infrastructure as code(IaC) configurations and turn it into real infrastructure on any provider.
There are three core elements to the Terraform collaboration experience:
State management: Store, secure, lock, and version Terraform state files
Centralized plans and applies: Safely run Terraform plans and applies in one location where collaborators can review and make decisions together
Module registry: Share reusable Terraform modules across a team
$ git clone <repository-url>
$ cd <repository-directory>
$ terraform init
$ terraform plan
$ terraform apply
📝Terraform Best Practices
Follow a standard module structure
Terraform modules must follow the standard module structure.
Start every module with a
main.tffile, where resources are located by default.In every module, include a
README.mdfile in Markdown format. In theREADME.mdfile, include basic documentation about the module.Place examples in a
examples/folder, with a separate subdirectory for each example. For each example, include a detailedREADME.mdfile.Create logical groupings of resources with their own files and descriptive names, such as
network.tf,instances.tf, orloadbalancer.tf.- Avoid giving every resource its own file. Group resources by their shared purpose. For example, combine
aws_dns_managed_zoneandaws_dns_record_setindns.tf.
- Avoid giving every resource its own file. Group resources by their shared purpose. For example, combine
In the module's root directory, include only Terraform (
*.tf) and repository metadata files (such asREADME.mdandCHANGELOG.md).Place any additional documentation in a
docs/subdirectory.
Adopt a naming convention
Name all configuration objects using underscores to delimit multiple words. This practice ensures consistency with the naming convention for resource types, data source types, and other predefined values. This convention does not apply to name arguments.
Recommended:
resource "compute_instance" "web_server" { name = "web-server" }Not recommended:
resource "compute_instance" "web-server" { name = "web-server" }To simplify references to a resource that is the only one of its type (for example, a single load balancer for an entire module), name the resource
main.- It takes extra mental work to remember
some_resource.my_special_resource.idversussome_resource.main.id.
- It takes extra mental work to remember
To differentiate resources of the same type from each other (for example,
primaryandsecondary), provide meaningful resource names.Make resource names singular.
In the resource name, don't repeat the resource type. For example:
Recommended:
resource "compute_global_address" "main" { ... }Not recommended:
resource "compute_global_address" "main_global_address" { … }Use variables carefully
Declare all variables in
variables.tf.Give variables descriptive names that are relevant to their usage or purpose:
Inputs, local variables, and outputs representing numeric values—such as disk sizes or RAM size—must be named with units (such as
ram_size_gb).To simplify conditional logic, give boolean variables positive names—for example,
enable_external_access.Variables must have descriptions. Descriptions are automatically included in a published module's auto-generated documentation. Descriptions add additional context for new developers that descriptive names cannot provide.
Give variables defined types.
When appropriate, provide default values:
For variables that have environment-independent values (such as disk size), provide default values.
For variables that have environment-specific values (such as
project_id), don't provide default values. This way, the calling module must provide meaningful values.Using empty defaults for variables (like empty strings or lists) only when leaving the variable empty is a valid preference that the underlying APIs don't reject.
Be judicious in your use of variables. Only parameterize values that must vary for each instance or environment. When deciding whether to expose a variable, ensure that you have a concrete use case for changing that variable. If there's only a small chance that a variable might be needed, don't expose it.
Adding a variable with a default value is backwards-compatible.
Removing a variable is backwards-incompatible.
In cases where a literal is reused in multiple places, you can use a local value without exposing it as a variable.
Expose outputs
Organize all outputs in a
outputs.tffile.Provide meaningful descriptions for all outputs.
Document output descriptions in the
README.mdfile. Auto-generate descriptions on commit with tools like terraform-docs.Output all useful values that root modules might need to refer to or share. Especially for open source or heavily used modules, expose all outputs that have the potential for consumption.
Don't pass outputs directly through input variables, because doing so prevents them from being properly added to the dependency graph. To ensure that implicit dependencies are created, make sure that outputs reference attributes from resources. Instead of referencing an input variable for an instance directly, pass the attribute through as shown here:
Recommended:
output "name" { description = "Name of instance" value = compute_instance.main.name }Not recommended:
output "name" { description = "Name of instance" value = var.name }
Use data sources
Put data sources next to the resources that reference them. For example, if you are fetching an image to be used in launching an instance, place it alongside the instance instead of collecting data resources in its own file.
If the number of data sources becomes large, consider moving them to a dedicated
data.tffile.To fetch data relative to the current environment, use variable or resource interpolation.
Limit the use of custom scripts
Use scripts only when necessary. The state of resources created through scripts is not accounted for or managed by Terraform.
Avoid custom scripts, if possible. Use them only when Terraform resources don't support the desired behaviour.
Any custom scripts used must have a clearly documented reason for existing and ideally a deprecation plan.
Terraform can call custom scripts through provisioners, including the local-exec provisioner.
Put custom scripts called by Terraform in a
scripts/directory.
Include helper scripts in a separate directory
Organize helper scripts that aren't called by Terraform in a
helpers/directory.Document helper scripts in the
README.mdfile with explanations and example invocations.If helper scripts accept arguments, provide argument-checking and
--helpoutput.
Put static files in a separate directory
Static files that Terraform references but don't execute (such as startup scripts loaded onto Compute Engine instances) must be organized into a
files/directory.Place lengthy HereDocs in external files, separate from their HCL. Reference them with the
file()function.For files that are read in by using the Terraform
templatefilefunction, use the file extension.tftpl.- Templates must be placed in a
templates/directory.
- Templates must be placed in a
Protect stateful resources
For stateful resources, such as databases, ensure that deletion protection is enabled. For example:
resource "sql_database_instance" "main" {
name = "primary-instance"
settings {
tier = "D0"
}
lifecycle {
prevent_destroy = true
}
}
Use built-in formatting
All Terraform files must conform to the standards of terraform fmt.
Limit the complexity of expressions
Limit the complexity of any individual interpolated expressions. If many functions are needed in a single expression, consider splitting it out into multiple expressions by using local values.
Never have more than one ternary operation in a single line. Instead, use multiple local values to build up the logic.
Don't configure providers or backends
Shared modules must not configure providers or backends. Instead, configure providers and backends in root modules.
For shared modules, define the minimum required provider versions in a required_providers block, as follows:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = ">= 5.0.0"
}
}
}
Unless proven otherwise, assume that new provider versions will work.
Expose labels as a variable
Allow flexibility in the labelling of resources through the module's interface. Consider providing a labels variable with a default value of an empty map, as follows:
variable "labels" {
description = "A map of labels to apply to contained resources."
default = {}
type = "map"
}
Expose outputs for all resources
Variables and outputs let you infer dependencies between modules and resources. Without any outputs, users cannot properly order your module in relation to their Terraform configurations.
For every resource defined in a shared module, include at least one output that references the resource.
Use inline submodules for complex logic
Inline modules let you organize complex Terraform modules into smaller units and de-duplicate common resources.
Place inline modules in
modules/$modulename.Treat inline modules as private, not to be used by outside modules, unless the shared module's documentation specifically states otherwise.
Terraform doesn't track refactored resources. If you start with several resources in the top-level module and then push them into submodules, Terraform tries to recreate all refactored resources. To mitigate this behaviour, use
movedblocks when refactoring.Outputs defined by internal modules aren't automatically exposed. To share outputs from internal modules, re-export them.
Minimize the number of resources in each root module
It is important to keep a single root configuration from growing too large, with too many resources stored in the same directory and state. All resources in a particular root configuration are refreshed every time Terraform is run. This can cause slow execution if too many resources are included in a single state. A general rule: Don't include more than 100 resources (and ideally only a few dozen) in a single state.
Use separate directories for each application
To manage applications and projects independently of each other, put resources for each application and project in their own Terraform directories. A service might represent a particular application or a common service such as shared networking. Nest all Terraform code for a particular service under one directory (including subdirectories).
Split applications into environment-specific subdirectories
When deploying services in AWS Cloud, split the Terraform configuration for the service into two top-level directories: a modules directory that contains the actual configuration for the service, and an environments directory that contains the root configurations for each environment.
-- SERVICE-DIRECTORY/
-- OWNERS
-- modules/
-- <service-name>/
-- main.tf
-- variables.tf
-- outputs.tf
-- provider.tf
-- README
-- ...other…
-- environments/
-- dev/
-- backend.tf
-- main.tf
-- qa/
-- backend.tf
-- main.tf
-- prod/
-- backend.tf
-- main.tf
Use environment directories
To share code across environments, and reference modules. Typically, this might be a service module that includes the base shared Terraform configuration for the service. In service modules, hard-code common inputs only require environment-specific inputs as variables.
Each environment directory must contain the following files:
A
backend.tffile, declaring the Terraform backend state location (i.e AWS S3 Bucket)A
main.tffile that instantiates the service module
Each environment directory (dev, qa, prod) corresponds to a default Terraform workspace and deploys a version of the service to that environment. These workspaces isolate environment-specific resources into their own contexts. Use only the default workspace.
Having multiple CLI workspaces within an environment isn't recommended for the following reasons:
It can be difficult to inspect the configuration in each workspace.
Having a single shared backend for multiple workspaces isn't recommended because the shared backend becomes a single point of failure if it is used for environment separation.
While code reuse is possible, code becomes harder to read having to switch based on the current workspace variable (for example,
terraform.workspace == "foo" ? this : that).
For more information, see the following:
Expose outputs through remote state
Export as output information from a root module that other root modules might depend on. In particular, make sure to re-export nested module outputs that are useful as a remote state.
Other Terraform environments and applications can reference root module-level outputs only.
By using the remote state, you can reference root module outputs. To allow use by other dependent apps for configuration, export to remote state information that's related to a service's endpoints.
Sometimes, such as when invoking a shared service module from environment directories, it is appropriate to re-export the entire child module, as follows:
output "service" {
value = module.service
description = "The service module outputs"
}
Pin to minor provider versions
In root modules, declare each provider and pin it to a minor version. This allows automatic upgrades to new patch releases while still keeping a solid target. For consistency, name the versions file versions.tf.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0.0"
}
}
}
Store variables in a tfvars file
For root modules, provide variables by using a .tfvars variables file. For consistency, name variable files terraform.tfvars.
Don't specify variables by using alternative var-files or var='key=val' command-line options. Command-line options are ephemeral and easy to forget. Using a default variables file is more predictable.
Check in .terraform.lock.hcl file
For root modules, the .terraform.lock.hcl dependency lock file should be checked into source control. This allows for tracking and reviewing changes in provider selections for a given configuration.
Cross-configuration communication
A common problem that arises when using Terraform is how to share information across different Terraform configurations (possibly maintained by different teams). Generally, information can be shared between configurations without requiring that they be stored in a single configuration directory (or even a single repository).
The recommended way to share information between different Terraform configurations is by using a remote state to reference other root modules. i.e. AWS S3 Bucket or Terraform Enterprise are the preferred state backends.
For querying resources that are not managed by Terraform, use data sources from the Cloud provider. Don't use data sources to query resources that are managed by another Terraform configuration. Doing so can create implicit dependencies on resource names and structures that normal Terraform operations might unintentionally break.
Manage Identity and Access Management
When provisioning IAM associations with Terraform.
Create authoritative IAM associations, where the Terraform resources serve as the only source of truth for what permissions can be assigned to the relevant resource.
If the permissions change outside of Terraform, Terraform on its next execution overwrites all permissions to represent the policy as defined in your configuration. This might make sense for resources that are wholly managed by a particular Terraform configuration, but it means that roles that are automatically managed by AWS Cloud are removed—potentially disrupting the functionality of some services.
Version control
As with other forms of code, store infrastructure code in version control to preserve history and allow easy rollbacks.
Use a default branching strategy
For all repositories that contain Terraform code, use the following strategy by default:
The
mainbranch is the primary development branch and represents the latest approved code. Themainbranch is protected.Development happens on feature and bug-fix branches that branch off of the
mainbranch.Name feature branches
feature/$feature_name.Name bug-fix branches
fix/$bugfix_name.
When a feature or bug fix is complete, merge it back into the
mainbranch with a pull request.To prevent merge conflicts, rebase branches before merging them.
Use environment branches for root configurations
For repositories that include root configurations that are directly deployed to AWS Cloud, a safe rollout strategy is required. We recommend having a separate branch for each environment. Thus, changes to the Terraform configuration can be promoted by merging changes between the different branches.
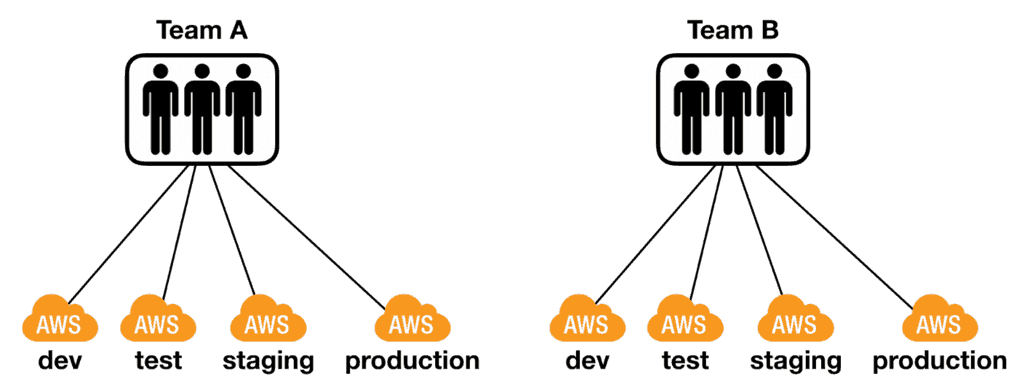
Allow broad visibility
Make Terraform source code and repositories broadly visible and accessible across engineering organizations, to infrastructure owners (for example, SREs) and infrastructure stakeholders (for example, developers). This ensures that infrastructure stakeholders can have a better understanding of the infrastructure that they depend on.
Encourage infrastructure stakeholders to submit merge requests as part of the change request process.
Never commit secrets
Never commit secrets to source control, including in Terraform configuration. Instead, upload them to a system like Secret Manager and reference them by using data sources.
Keep in mind that such sensitive values might still end up in the state file and might also be exposed as outputs.
Organize repositories based on team boundaries
Although you can use separate directories to manage logical boundaries between resources, organizational boundaries and logistics determine repository structure. In general, use the design principle that configurations with different approval and management requirements are separated into different source control repositories. To illustrate this principle, these are some possible repository configurations:
One central repository: In this model, all Terraform code is centrally managed by a single platform team. This model works best when there is a dedicated infrastructure team responsible for all cloud management and approves any changes requested by other teams.
Team repositories: In this model, each team is responsible for their own Terraform repository where they manage everything related to the infrastructure they own. For example, the security team might have a repository where all security controls are managed, and application teams each have their own Terraform repository to deploy and manage their application.
Organizing repositories along team boundaries is the best structure for most enterprise scenarios.
Decoupled repositories: In this model, each logical Terraform component is split into its own repository. For example, networking might have a dedicated repository, and there might be a separate project factory repository for project creation and management. This works best in highly decentralized environments where responsibilities frequently shift between teams.
Sample repository structure
You can combine these principles to split Terraform configuration across different repository types: Foundational / Application and team-specific / Foundational repository
Always plan first
Always generate a plan first for Terraform executions. Save the plan to an output file. After an infrastructure owner approves it, execute the plan. Even when developers are locally prototyping changes, they should generate a plan and review the resources to be added, modified, and destroyed before applying the plan.
Implement an automated pipeline
To ensure consistent execution context, execute Terraform through automated tooling. If a build system (like Jenkins) is already in use and widely adopted, use it to run the terraform plan and terraform apply commands automatically. If no existing system is available, adopt either AWS Code Pipeline or Terraform Cloud.
Use service account credentials for continuous integration
When Terraform is executed from a machine in a CI/CD pipeline, it should inherit the service account credentials from the service executing the pipeline. For pipelines that run elsewhere, prefer workload identity federation to obtain credentials. Use downloaded service account keys as a last resort.
Avoid importing existing resources
Where possible, avoid importing existing resources (using terraform import), because doing so can make it challenging to fully understand the provenance and configuration of manually created resources. Instead, create new resources through Terraform and delete the old resources.
In cases where deleting old resources would create significant toil, use the terraform import command with explicit approval. After a resource is imported into Terraform, manage it exclusively with Terraform.
Don't modify Terraform state manually
The Terraform state file is critical for maintaining the mapping between Terraform configuration and AWS Cloud resources. Corruption can lead to major infrastructure problems. When modifications to the Terraform state are necessary, use the terraform state command.
Regularly review version pins
Pinning versions ensures stability but prevents bug fixes and other improvements from being incorporated into your configuration. Therefore, regularly review version pins for Terraform, Terraform providers, and modules.
To automate this process, use a tool such as Dependabot.
Use application default credentials when running locally
Don't download service account keys, because downloaded keys are harder to manage and secure.
Set aliases to Terraform
To make local development easier, you can add aliases to your command shell profile:
alias tf="terraform"alias terrafrom="terraform"
Use remote state
Make sure that only the build system and highly privileged administrators can access the bucket that is used for the remote state.
To prevent accidentally committing the development state to source control, use gitignore for Terraform state files.
Encrypt state
Though AWS Cloud buckets are encrypted at rest, you can use customer-supplied encryption keys to provide an added layer of protection. Do this by using the GOOGLE_ENCRYPTION_KEY environment variable. Even though no secrets should be in the state file, always encrypt the state as an additional measure of defence.
Don't store secrets in state
There are many resources and data providers in Terraform that store secret values in plaintext in the state file. Where possible, avoid storing secrets in state. Following are some examples of providers that store secrets in plaintext:
Mark sensitive outputs
Instead of attempting to manually encrypt sensitive values, rely on Terraform's built-in support for sensitive state management. When exporting sensitive values to output, make sure that the values are marked as sensitive.
Ensure separation of duties
If you can't run Terraform from an automated system which no users have access, adhere to a separation of duties by separating permissions and directories. For example, a network project would correspond with a network Terraform service account or user whose access is limited to this project.
Run continuous audits
After the terraform apply command has executed, run automated security checks. These checks can help to ensure that infrastructure doesn't drift into an insecure state. The following tools are valid choices for this type of check:
Testing
Testing Terraform modules and configurations sometimes follow different patterns and conventions from testing application code. While testing application code primarily involves testing the business logic of applications themselves, fully testing infrastructure code requires deploying real cloud resources to minimize the risk of production failures. There are a few considerations when running Terraform tests:
Running a Terraform test creates, modifies, and destroys real infrastructure, so your tests can potentially be time-consuming and expensive.
You cannot purely unit test an end-to-end architecture. The best approach is to break up your architecture into modules and test those individually. The benefits of this approach include faster iterative development due to faster test runtime, reduced costs for each test, and reduced chances of test failures from factors beyond your control.
Avoid reusing state if possible. There may be situations where you are testing with configurations that share data with other configurations, but ideally, each test should be independent and should not reuse state across tests.
Use less expensive test methods first
There are multiple methods that you can use to test Terraform. In ascending order of cost, run time, and depth, they include the following:
Static analysis: Testing the syntax and structure of your configuration without deploying any resources, using tools such as compilers, linters, and dry runs. To do so, use
terraform validate.Module integration testing: To ensure that modules work correctly, test individual modules in isolation. Integration testing for modules involves deploying the module into a test environment and verifying that expected resources are created.
End-to-end testing: By extending the integration testing approach to an entire environment, you can confirm that multiple modules work together. In this approach, deploy all modules that make up the architecture in a fresh test environment. Ideally, the test environment is as similar as possible to your production environment. This is costly but provides the greatest confidence that changes don't break your production environment.
Start small
Make sure that your tests iteratively build on each other. Consider running smaller tests first and then working up to more complex tests, using a fail-fast approach.
Randomize project IDs and resource names
To avoid naming conflicts, make sure that your configurations have a globally unique project ID and non-overlapping resource names within each project. To do this, use namespaces for your resources. Terraform has a built-in random provider for this.
Use a separate environment for testing
During testing, many resources are created and deleted. Ensure that the environment is isolated from development or production projects to avoid accidental deletions during resource cleanup. The best approach is to have each test create a fresh project or folder. To avoid misconfiguration, consider creating service accounts specifically for each test execution.
Clean up all resources
Testing infrastructure code means that you are deploying actual resources. To avoid incurring charges, consider implementing a clean-up step.
To destroy all remote objects managed by a particular configuration, use the terraform destroy command. Some testing frameworks have a built-in cleanup step for you. For example, if you are using Terratest, add defer terraform.Destroy(t, terraformOptions)to your test. If you're using Kitchen-Terraform, delete your workspace using terraform kitchen delete WORKSPACE_NAME.
After you run the terraform destroy command, also run additional clean-up procedures to remove any resources that Terraform failed to destroy. Do this by deleting any projects used for test execution or by using a tool like a project_cleanup module.
Optimize test runtime
To optimize your test execution time, use the following approaches:
Run tests in parallel. Some testing frameworks support running multiple Terraform tests simultaneously.
- For example, with Terratest you can do this by adding
t.Parallel()after the test function definition.
- For example, with Terratest you can do this by adding
Test in stages. Separate your tests into independent configurations that can be tested separately. This approach removes the need to go through all stages when running a test and accelerates the iterative development cycle.
For example, in Kitchen-Terraform, split tests into separate suites. When iterating, execute each suite independently.
Similarly, using Terratest, wrap each stage of your test with
stage(t, STAGE_NAME, CORRESPONDING_TESTFUNCTION). Set environment variables that indicate which tests to run. For example,SKIPSTAGE_NAME="true".The blueprint testing framework supports staged execution.
In this blog post, you learned more about Terraform's advanced topics and the principal best practices for its use.
Thank you for reading. I hope you were able to understand and learn something helpful from my blog.
Please follow me on Hashnode and on LinkedIn franciscojblsouza